发现问题
3月8日收到线上部分区域监控系统报警,提示数据处理服务大批异常报警;登录机器查看系统负载情况: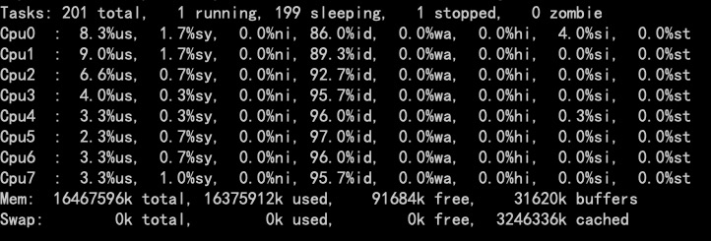
系统CPU占用并不高。
同事提示,发现了HSF日志中输出了HSF连接池满的情况: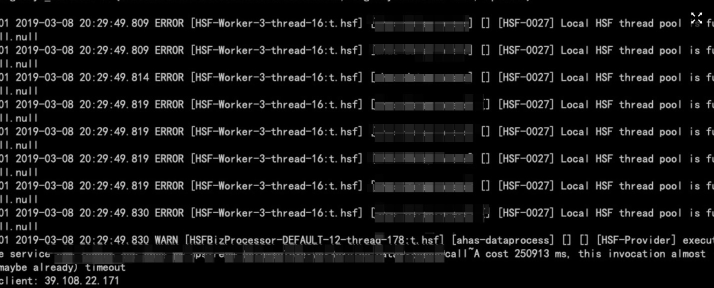
第一反应是后端处理太慢导致,查看了数据处理耗时统计:
发现峰值耗时已经超过了160秒;
处理方案:
暂且为定位根因,先做了服务器重启;重启后恢复,以为是偶发情况;
介入排查
3月12 ~ 15日之间 线上Dataprocess的报警频次越来越高,且数量越来越大。在3月15日进行系统问题定位于排查;
分析代码后,做了一下优化:
- 接受日志处理的线程池的队列之前采用的是ArrayBlockingQueue,改用双锁队列LinkedBlockingQueue;
- 线程池拒绝策略采用自定义的DiscardPolicy,不再使用DiscardOldestPolicy(会进行队列poll操作,需要竞争锁);
- 增加了线程池监控,监控线程池队列大小、处理任务数、丢弃任务数;
具体定位
指标观察:
系统发布后,问题并未得到解决,报警依旧,采用tsar 观察系统各项指标: (系统load,对于8core cpu,load并不高)
(系统load,对于8core cpu,load并不高)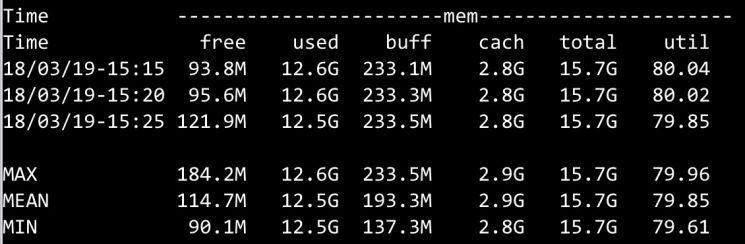 (系统剩余内存不足)
(系统剩余内存不足) (系统的io操作并不频繁)
(系统的io操作并不频繁)
开始怀疑jvm参数配置有错误,查了jvm的堆内存分配,从参数和合理上看并没有太大问题。
堆分配如下:
启动时堆的初始化大小: 10G(-Xms)
堆最大值为: 10G(-Xmx)
年轻代空间大小:4G(-Xmn)
初始持久代:256m (-XX:MetaspaceSize)
最大持久代:512m (-XX:MaxMetaspaceSize)
Jstack分析:
开始对线上系统进行jstack,分析线程栈具体卡在什么地方;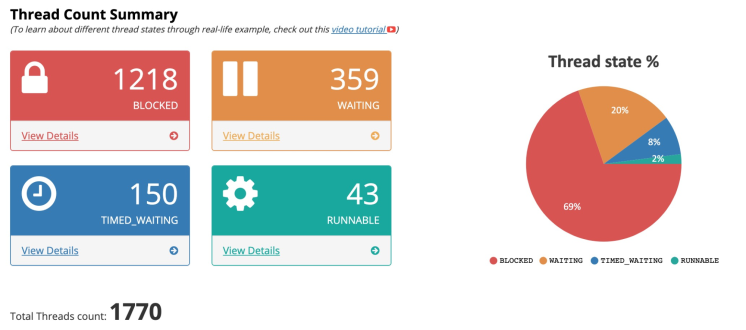
发现 69%的线程处于blocked状态;
从线程分组上看,HSFBizProcessor基本全部处于Blocked状态,log-handler-thread线程所有都处于blocked状态;

查看处于blocked的HSF线程栈信息:
1 | HSFBizProcessor-DEFAULT-12-thread-1673 - priority:10 - threadId:0x0000000006d32000 - nativeId:0x4f72 - nativeId (decimal):20338 - state:BLOCKED |
发现block在transport-api 包中的hanler方法中,查看代码: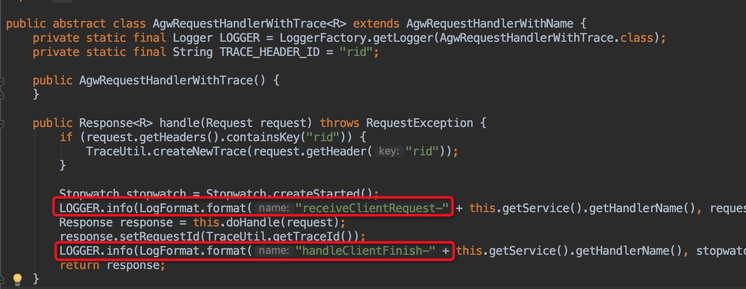
发现是日志输出中CachingDateFormatter的SimpleDateFormat 获得的锁未释放。
优化方案:
- 取消transport-api中的日志输出,认为此没有必要,且输出的日志量巨大;
- 打印日志优化:日志格式优化-减少不重要信息,降低系统调用,日志采用AsyncAppender包装RollingFileAppender,使用异步日志输出;

代办事项:排查打日志导致的锁未释放的真正原因。
发布系统后,继续观察,重启后的一段时间,系统表现正常,但是一段时间后,又有报警出来:
初步怀疑跟jstack有关,但是jstack时间是 18点40分左右,报警是在19点整,对不上。
从网关侧看到此区域的qps情况,波动非常大;
初步诊断:
由于没有限流,北京的量太大,历史堆积太对,导致长时间堆积的数据上来后直接把系统打爆了,agent侧没有做流控,服务侧接受方也没有做流控导致的。
解决方案:
- 采用AHAS 流控降级服务增加限流,对于历史数据直接丢弃,对于新请求增加流控;
第二天,从管控后台上看到北京SLA剧烈波动:
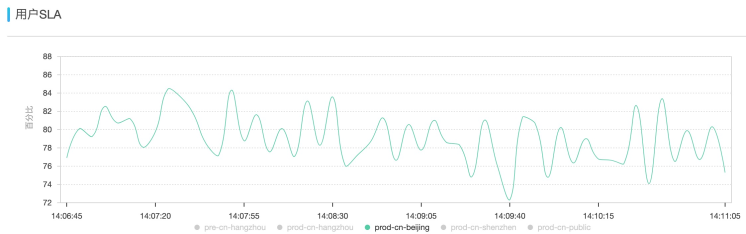
对此区域一台机器进行offline,然后jstack线程栈继续分析:

提取hsf的jstack,发现,系统中 业务的处理并没有走统一的线程池处理方案;
优化方案:
- 抽取公共代码,定义日志和业务日志抽象类,分别使用线程池进行处理;
GC分析:
对系统的GC日志进行了分析:
发现频繁触发fgc,且fgc失败,old区 非常大,gc无法回收,怀疑存在大对象导致的内存无法回收。
通过jmap查看进程占用的大对象;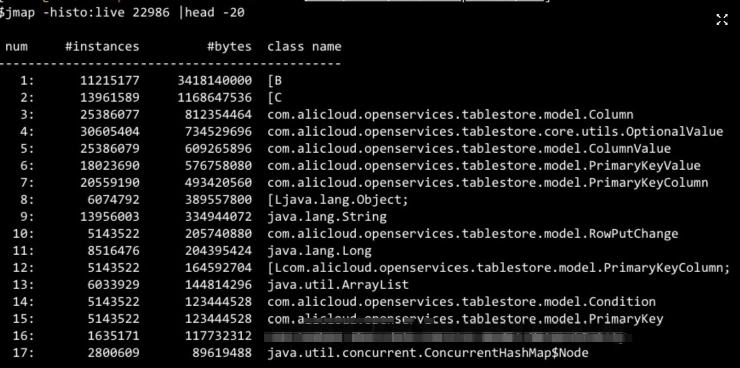
发现系统内存中ots对象数据占用超过3G;与OTS同学沟通后,发现是client的使用问题。
问题解决:
OTS写入优化,改用tablestoreWrite代替AyncClient,增加线程数控制、内存buffer控制等;
- AyncClient处理时,当线程池满之后,会把新进来的数据全部堆在内存中,会导致内存占满;
- tablestoreWrite采用了RingBuffer无锁写入,当线程池满且队列满之后,会阻塞调用线程;
新问题出现:
系统灰度上线后,OTS写数据出现hang住;出现数据洪峰,导致处理线程block;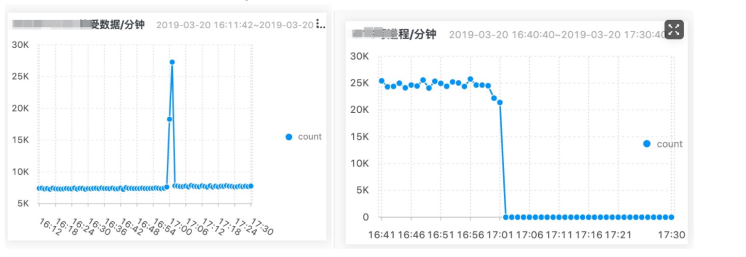
此时 jstack数据如下: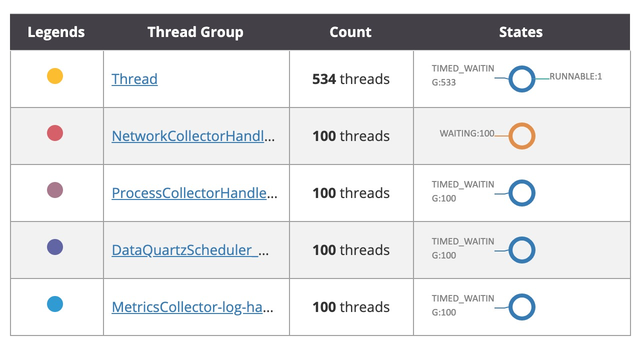

解决方案:
- 拆分线程池; 不能因为写监控数据而导致进程数据无法写入;进程的数据量与监控指标的数据量 不再一个数量级上。
- 针对ots数据写入增加限流保护,并进行block数据统计;
- 进一步定位导致TableStoreWriter写数据卡主的问题;
对系统进行offline,观察线程池队列处于满状态,预期是不再有新流量进来时,线程池队列数据会被消费,但是观察了二十分钟后,线程池队列数据依然处于慢状态,说明线程hang住了。
升级到OTS新版本后,持续观察,一段时间后,问题继续浮现。在仔细review代码,发现消费RingBuffer的线程池的拒绝策略采用了DiscardPolicy丢弃,也就是当系统处理不过来时进行丢弃,但是请求丢弃了会导致外层的线程hang住;
具体为什么这里的线程池采用discard策略后会导致线程hang住,OTS同学给出的解释是“RingBuffer的数据会丢到线程池里处理,通过Semaphore来协同,如果executor丢弃了请求,那外层就会hang住”,此设计缺失不优雅,算是OTS Client的一个bug。
最终解决:
- 修改线程池的拒绝策略后,灰度部分机器持续观察(上一次线上出现问题的时间周期大约为1小时,并且在一个波峰请求之后)。
- 线上丢弃的日志量恢复为0,且写ots正常。
总结:
我们时刻需要对线上系统的容量和现状有清晰的了解,知道系统内存当前的水位,内存中那些线程在运行,什么数据对象会占用大量内存,系统还能接受多大的量,系统的极限负载是多少等。其次,对于线上稳定性问题定位,我们还需要熟练使用一套排查工具,辅助定位问题。
常用命令:
top ; # 查看系统CPU、Mem占用;
top -Hp pid; #查看具体进程下线程的cpu占用统计, pid到nid转换:printf ‘0x%x’;
iostat -d -k 1 10; # 统计磁盘IO;
tsar –cpu –mem –traffic –io ; #利用tsar来统计各项监控指标;
jmap -histo:live pid | head -20 #查看进程占用内存前20个对象;
jstack pid > jstack.log # 打印对应进程线程栈信息,常配合fastthread.io使用;
jstat –gcutil [pid] 1000 10 # 查看进程gc信息;
常用工具:
https://gceasy.io/ 用于分析gc日志;
https://fastthread.io/ 用于分析线程栈;
https://github.com/alibaba/arthas Arthas;
