背景
业务上有一个需求使用基线数据中拷贝出内容,分发到不同用户集合的存储实例中,使用模型标识就是B->(u1,u2,u3…uN),初始代码逻辑是,每个用户都有单独的定时器触发来执行B->uN的拷贝,执行这个过程需要首先从基线B中取出数据,然后替换为uN的用户信息,在写入uN的数据存储中(用户之间逻辑隔离非物理隔离),期初此流程没什么问题,后来考虑到每个用户读取的基线可能相同,可以对基线数据做local cache,以此来优化程序的执行性能, local cache 变量为全局共享变量,多线程可访问。
问题
在做性能优化使用local cache的时候,会先查询缓存是否存在,如果不存在,则查询基线数据,如果查询的基线存在的话,则回写到缓存中,并向目标用户实例中写入基线数据,整体流程如下:
1 | //首先查本地缓存 |
增加了缓存后,我们在编码的时候,很容易认为数据我已经写到缓存中了,再对数据做处理不会影响缓存,但是我们忽略了这里的缓存是本地缓存,且是对象引用下的本地缓存,是共享数据;如果使用分布式缓存,通过数据的序列化和反序列化,相当于对象做了拷贝,不会有问题,如果使用本地缓存,存储数据的副本的话,也不会有问题;但是这里偏偏使用了本地变量,并对数据做了变更,没有引起编码时的注意,导致了错误。这个错误在单元测试的时候,也没测出来,发到生产环境上才对发现存储层在数据写入时大量报写入冲突。
解决
使用本地缓存时,如果有数据变更的需求,则需要使用副本,这也是共享变量在多线程中容易导致的一个容易发生的错误。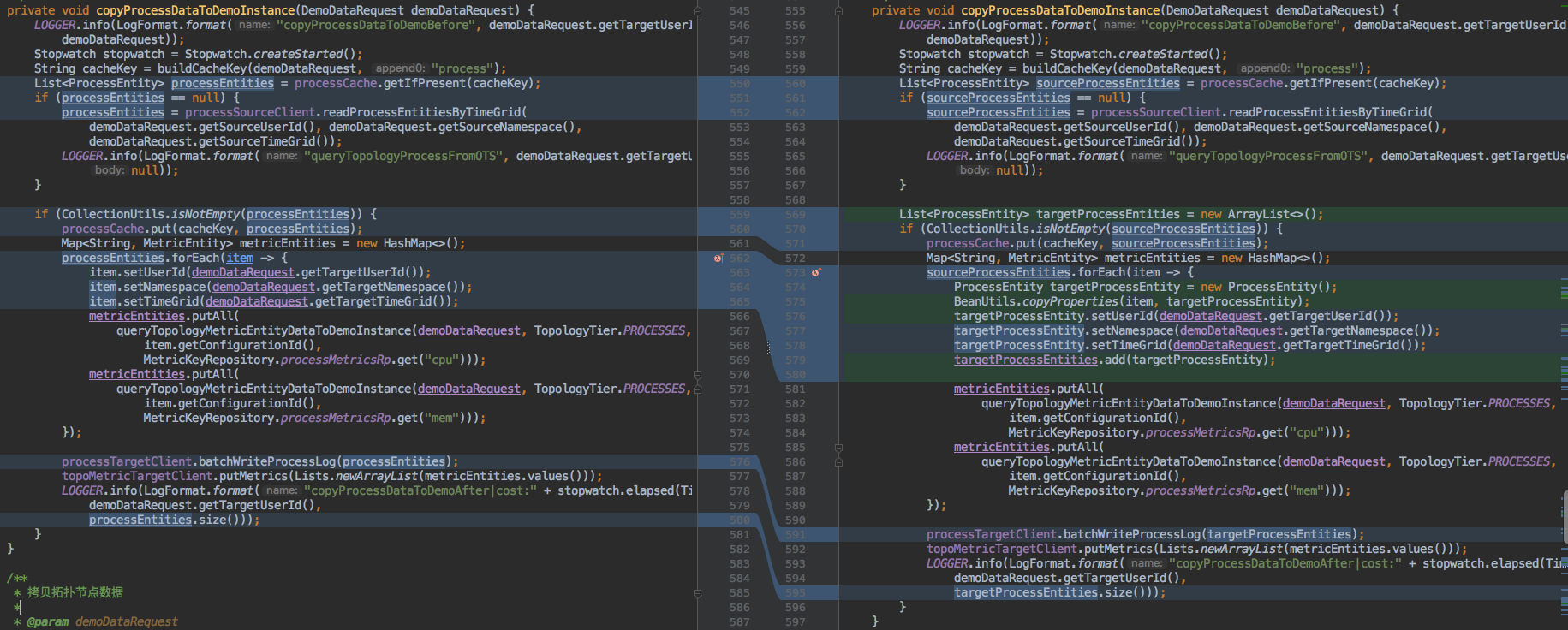
反思
期初线上打印出了冲突的问题,总以为是存储这边分批写的问题,后来发现这个问题的发生频次是间歇性的,且无规律,更像是具备随机性,所以决定深入排查,最后发现了编码上的一个很低级的错误。我们不要放过线上任何一个异常,除非我们把问题弄清楚了,否则“墨菲定律”告诉我们,担心出问题的地方,一定会出问题。
