背景:
A发消息给B系统,A、B应用的编码均为UTF-8,但是B收到的消息出现中文乱码。
A发送消息的方式:
1 | new Message(TOPIC, TAG, null, (messageContent.toString()).getBytes()) |
这里消息接受二进制byte数据,我们把消息string转换为byte的时候,默认使用了getBytes(),未指定编码方式,getBytes()方法的注释如下:
Encodes this {@code String} into a sequence of bytes using the
platform’s default charset, storing the result into a new byte array.
也就是会使用平台默认编码,查看StringCoding.encode方法中的Charset.defaultCharset().name()方法:
1 | /** |
注释的很清楚了,返回JVM默认的字符编码,如果在jvm启动参数中指定了-Dfile.encoding 编码,则优先使用此编码,如果未指定,则使用UTF-8编码;
登录服务器查看启动参数,发现A应用进程中指定了-Dfile.encoding=GB18030
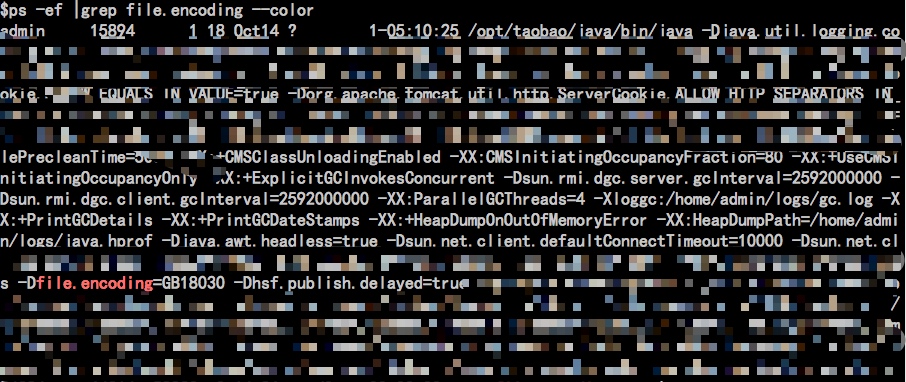
示意图如下: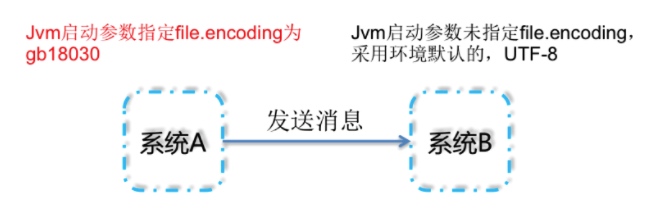
总结:
在进行string与byte转换的时候,最好使用getBytes(String charsetName)方法,明确指定字符编码方式,最好编写一个编码转换的工具类,统一类型转换时的编码方式。
