背景:
对于后端程序员来说,经常会遇到使用POI对excel进行上传与下载的需求,掌握一套高效的文件下载核心库和核心方法,会让我们日常编码效率变得更高。本文针对几种常见的的文件下载场景进行阐述如何高效实现文件下载。
一、了解HttpServletResponse:
不了解servlet及其工作原理的,建议先学习许令波写的Servlet 工作原理解析。
当服务端返回到数据给浏览器时,浏览器怎么知道是按照文本解析呢还是以附件的形式保存文件?这就涉及到了请求响应体(HttpServletResponse)中的两个重要参数:contentType、Content-Disposition;
HttpServletResponse 继承了ServletResponse接口,增加了http特性相关的一系列方法。
HttpServletResponse对象代表服务器的响应。这个对象中封装了向客户端发送数据、发送响应头,发送响应状态码的方法。查看HttpServletResponse的API,可以看到这些相关的方法。
1.1、负责向客户端(浏览器)发送数据的相关方法

这两个方法继承自ServletResponse接口,分为二进制输出(一般用于文件下载)、字符输出;
1.2、负责向客户端(浏览器)发送响应头的相关方法


1.3、负责向客户端(浏览器)发送重定向的相关方法


1.4、负责向客户端(浏览器)发送错误信息的相关方法


图中的四种处理响应的方式,都是通过HttpServletResponse对象来完成的: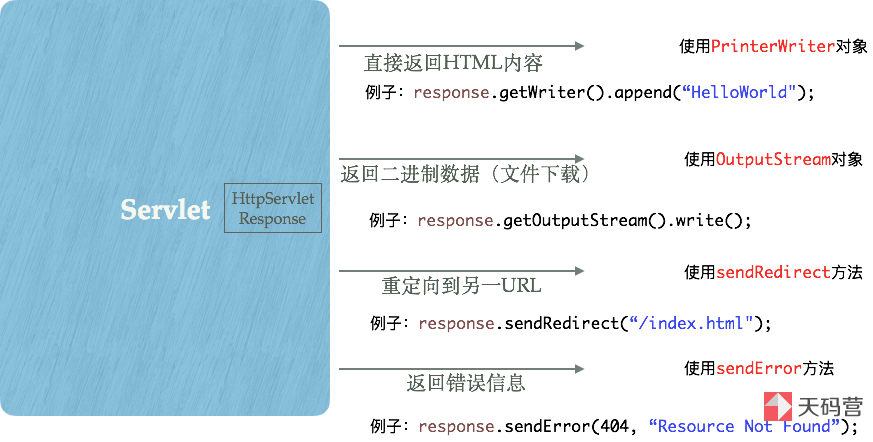
二、静态资源下载:
静态资源包括web服务器上或者云存储上的静态资源下载,这部分只需要我们配置化一定的请求过滤器即可实现下载,这里不做过多阐述;一般情况下,提供资源下载的服务会使用类似于Nginx的Http Server,提高响应效率,tomcat更多的使用在动态http资源请求处理上;
三、动态资源下载:
有些场景下,我们需要下载的文件并不存在,而是实时根据查询条件生成的文件,比如写在的报表数据通过excel合适输出。
最早的HTTP协议中,并没有附加的数据类型信息,所有传送的数据都被客户程序解释为超文本标记语言HTML 文档,而为了支持多媒体数据类型,HTTP协议中就使用了附加在文档之前的MIME数据类型信息来标识数据类型。
MIME意为多功能Internet邮件扩展,它设计的最初目的是为了在发送电子邮件时附加多媒体数据,让邮件客户程序能根据其类型进行处理。然而当它被HTTP协议支持之后,它的意义就更为显著了。它使得HTTP传输的不仅是普通的文本,而变得丰富多彩。
3.1 设置contentType和Content-Disposition:
1 | httpServletResponse.setContentType("application/octet-stream"); |
application/octet-stream:
这是应用程序文件的默认值。意思是 未知的应用程序文件 ,浏览器一般不会自动执行或询问执行。浏览器会像对待 设置了 HTTP头Content-Disposition 值为“附件”的文件一样来对待这类文件。
Content-Disposition:
它是 MIME 协议的扩展,MIME 协议指示 MIME 用户代理如何显示附加的文件。
文件名中文被过滤问题:
当我们使用new String(fileName,”UTF-8”)时,文件名称中的中文被自动过滤掉了,原因是header中只支持ASCII。解决办法有三个:
- 使用iso8859-1字符编码;
此解决方案在IE浏览器下,下载的文件名称如果包含中文还是会出现乱码; - 使用URLEncoder.encode(fileName,”UTF-8”)进行转换;
注意这里文件名称字符如果使用urlencoder转换只支持UTF-8,不支持GBK; - 使用filename*=charset’lang’value
charset则是给浏览器指明以什么编码方式来还原中文文件名;比如:
1 | headers.add("Content-Disposition","attachment;filename*=UTF-8''"+URLEncoder.encode(fileName,"UTF-8")+".xls"); |
3.2 输出二进制流:
定义BufferedOutputStream 向httpServletResponse.getOutputStream()写入二进制文件:
1 | FileWriterWithEncoding fwwe = new FileWriterWithEncoding(file, "gb18030"); |
如果我们使用了easyExcel二方库,输出excel变得更加简单:
1 | ExcelWriter writer = new ExcelWriter(httpServletResponse.getOutputStream(), ExcelTypeEnum.XLS, true); |
写入数据过程中,注意中文乱码。
data.getBytes()是一个将字符转换成字节数组的过程,这个过程中一定会去查码表,如果是中文的操作系统环境,默认就是查找查GB18030的码表,将字符转换成字节数组的过程就是将中文字符转换成GB18030的码表上对应的数字,所以我们在带有中文的文件输出到中文环境时,尽可能使用GB18030编码;
GB2312是过时标准、GBK是微软标准、GB18030是国家标准;
关于中文字符编码:
- GB2312:1980年,一共收录了7445个字符,包括6763个汉字和682个其它符号。
- GBK:是微软对GB2312的扩展,向下兼容GB2312编码,出现于Windows 95简体中文版中,微软标准但不是国家标准。
- GB18030:2000年,取代了GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了一些少数民族文字。
- GB13000:GB13000等同于国际标准的《通用多八位编码字符集 (UCS)》 ISO10646.1,就是等同于Unicode的标准,代码页等等的都使用UTF的一套标准。
四、大文件下载
对于大文件的下载,建议服务端先将文件在本地生成后,上传到文件存储服务中心,用户再从存储中心下载,当然,我们也可以针对大文件实现多线程并发断点下载,提高下载速度;
