今天遇到一个场景:用于有一批数据需要批量处理,每一个任务的处理都会花费300~500ms的时间,如果列表为30个时,直接导致http请求超时了(设置的Http请求时间为10s)。所以期望服务端能够多线程执行任务,所有执行完毕后返回最终结果。
解决方案大家比较明确了,在外部接口无法被优化的场景下,只能将顺序执行的任务变为并行执行,Java提供了线程模型和线程池模型。但是要做到合理的利用线程池,必须对其原理了如指掌。
所以问题的解决方案是:
定义线程池对象
1 | protected BlockingQueue queue = new LinkedBlockingQueue(100); |
为什么不使用Executors工厂类提供的集中固定的线程池对象呢?
Executors工厂提供了以下集中常见的线程池(基本上都是通过不同参数实例化ThreadPoolExecutor得到):
- Executors.newFixedThreadPool 创建固定数量线程的线程池,线程空闲多久都不会自动关闭,直到线程池主动关闭。当我们线程数不均匀的时候,无法做到很好的扩容。
- Executors.newSingleThreadExecutor 创建单线程的线程池。
- Executors.newCachedThreadPool 创建无线程上限(Integer.MAX_VALUE)的线程池,默认线程空闲60秒后自动回收,防止资源浪费,因为无上限,所以就没必要使用阻塞队列来存储任务了,因为原则上线程池不会满,这里采用的是SynchronousQueue,这个阻塞队列要求每个插入操作必须等待另一个线程的对应移除操作,相当于一个数量为1的缓冲区,既然线程无上限,那SynchronousQueue的作用是什么呢,我猜想应该是线程池初始化线程是要时间,采用这样一个缓冲区就可以等待线程池中新的线程创建完毕后直接使用,而不是任务当代线程池中线程的创建。一般生产环境线程数受限于Jvm、Linux等限制不可能做到无限大,为了更高的可控性,不会直接使用此方法。
- Executors.newScheduledThreadPool 创建一个支持定时及周期性的任务执行的线程池,多数情况下可用来替代Timer类。
我们自定义线程池:
- corePoolSize(线程池的基本大小),而不是0,原因是线程空闲时,线程可以直接使用,而不需要等待新线程的创建,加快运行效率;
- maximumPoolSize(线程池最大大小),设置线程池的最大值而不是Integer.MAX_VALUE,因为我们需要做到资源可控,jvm、linux os的可创建线程数都是有限的(记一次系统Dubbo调用超时的故障);
- keepAliveTime(线程活动保持时间),为了加大线程的可用性,设置空闲线程的存活时间,不能太小,否则线程就一直处于销毁和创建过程,也不能太大,否则会是线程池长期处于满空闲状态,导致资源浪费,默认值为60s。
- runnableTaskQueue(任务队列),设置当线程池慢后的任务等待队列,ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序;LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue;PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
- RejectedExecutionHandler(饱和策略),当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。JDK提供了四种策略:AbortPolicy:直接抛出异常;CallerRunsPolicy:只用调用者所在线程来运行任务;DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务;DiscardPolicy:不处理,丢弃掉;所以我们推荐使用CallerRunsPolicy,保证业务不受严重影响。
当然这些参数具体该设置多少合适呢?在业务初期我们只能靠经验值才设置,但是运行过程中,我们是可以通过一些线程池的监控来做到调优我们的配置的。
顺便了解一下线程池的工作流程:
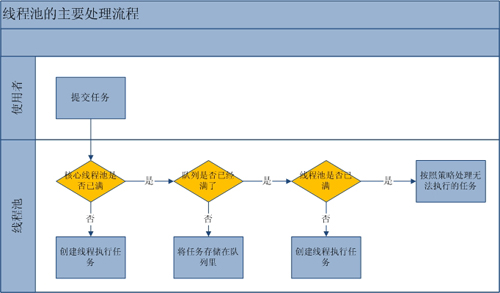
当核心线程数未满的时候,创新新的线程,当核心线程数慢了之后,新加入的任务会进入队列,当队列慢了后,如果最大核心数未满,则创建新的线程,如果最大核心数也满了,则使用配置的饱和策略来决定怎么处理新加入的线程。
CountDownLatch 记录并等待所有线程执行完毕
1 | //多线程处理 |
这里没有使用Executor的execute方法,使用的submit方法,他返回一个future,因为我们期望获取每一个线程执行的结果信息,我们需要统计那些执行失败了,那些执行成功了,方便做整体业务回滚。
通过这个future来判断任务是否执行成功,通过future的get方法来获取返回值,get方法会阻塞住直到任务完成,而使用get(long timeout, TimeUnit unit)方法则会阻塞一段时间后立即返回,这时有可能任务没有执行完。其次,我们还可以在submit方法中向外抛出业务异常,通过future.get()捕获异常,并处理异常。
相比循环判断每一个任务的返回结果是否都执行完毕了,通过计数器CountDownLatch来记录任务是否都完毕的方式更加简洁和清晰,性能也会更高一些。
可能会遇到的问题:
之前单线程处理的任务如果一个失败了,整个请求可以通过Spring的事务进行回滚,但是如果多线程处理的话,就无法做到失败回滚,如果业务允许部分失败,可以将失败的任务信息反馈给用户,如果业务上必须具有强原子性,所以需要自己实现回滚逻辑,比如每次把执行成功的和失败的都记录下来,后续统一处理回滚逻辑。
总结:
通过本次优化,之前的一直容易出现超时的问题得到了一定的优化,但是期望更高的性能的话,需要优化外部调用方的性能。
