排查方法:
首先找到cpu使用率高的进程:
1 | top |
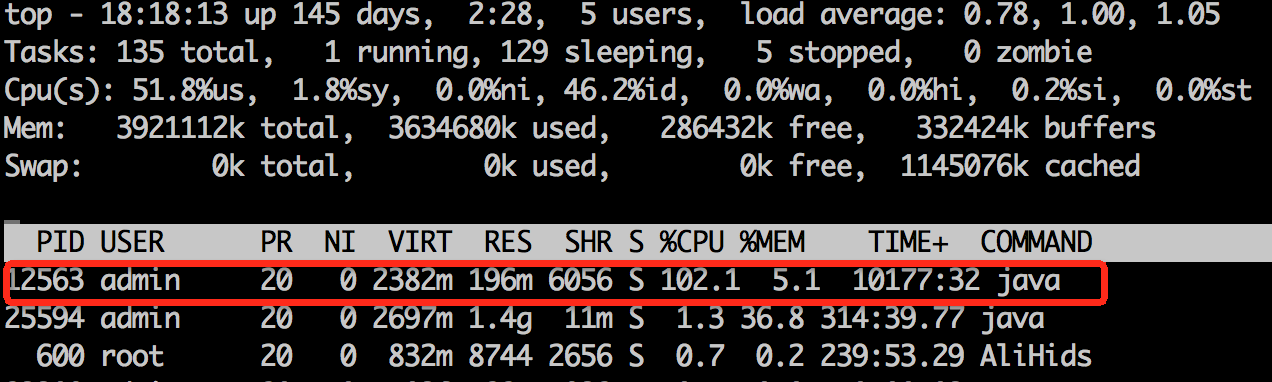
查看进程对应的应用信息:
1 | ps -ef |grep 进程id |

发现是小二后台的进程,由于没有配置gc日志,所以看不当gc日志,但是可通过其他方法排查;
打印堆栈信息,查找占用大量CPU的线程:
1 | jstack |
查看GC情况:
1 | jstat -gc |
每列的含义:
S0C Current survivor space 0 capacity (KB). 当前survivor0的容量
S1C Current survivor space 1 capacity (KB). 当前survivor1的容量
S0U Survivor space 0 utilization (KB). survivor0的使用
S1U Survivor space 1 utilization (KB). survivor1的使用
EC Current eden space capacity (KB). 当前eden的容量
EU Eden space utilization (KB). eden的使用
OC Current old space capacity (KB). 当前old的容量
OU Old space utilization (KB). old的使用
PC Current permanent space capacity (KB). 当前perm的容量
PU Permanent space utilization (KB). perm的使用
YGC Number of young generation GC Events. young gc的次数
YGCT Young generation garbage collection time. young gc的总时间
FGC Number of full GC events. full gc的次数
FGCT Full garbage collection time. full gc的总时间
GCT Total garbage collection time. 所有gc的总时间
从上图看到 Yong GC 次数不变,但是FGC的次数几乎每4s一次,一般FGC的触发是由于YGC触发,但是这个就比较特殊了,难道是主动调用了FGC?不会呀,从我们的启动脚本上看,我们禁止了主动调用GC(-XX:+DisableExplicitGC)。
重启后,发现没有再频繁的FGC了,恢复了正常,此时我们也同时开启了GC日志(-verbose:gc -Xloggc:/home/admin/logs/gc.log)。
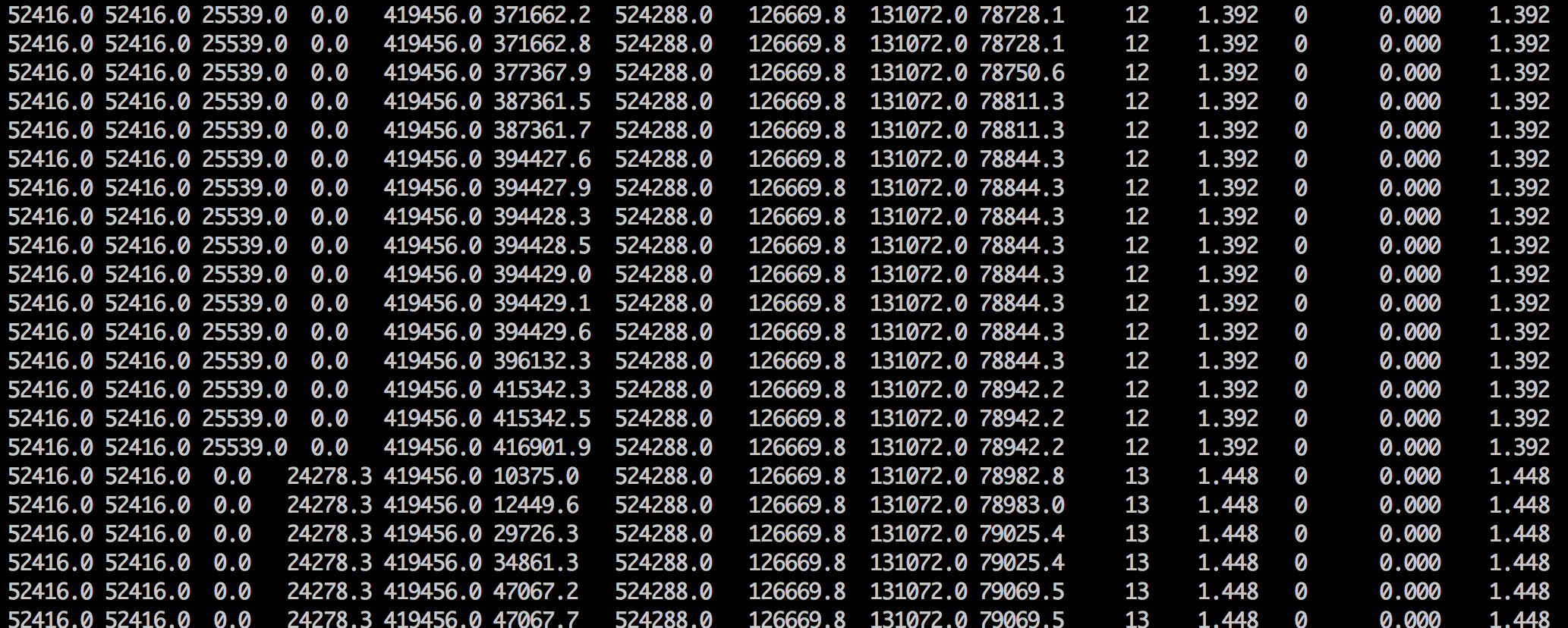
但是一天后又出现了同样的情况,CPU使用率飙高,FGC频繁,此时内存使用为1.3G。
那有没有可能是大对象在Eden内存不够分配,直接进入Old区,而Old区也不够触发了FGC呢?
通过分析,这种情况不台可能,首先我们看了Eden和Old区还剩余大量内存,通过Jmap也没有发现大对象。其次,我们使用的GC收集器是CMS,这种情况,CMS必定会触发YGC,因为CMS无法回收New区(至于为什么还需要查一些文档)。
根据之前毕玄大师给出的GC频繁的排查方法:

CMS GC频繁 的原因可能是缺少UseCMSInitiatingOccupancyOnly参数,而触发了JVM的悲观策略。
那什么是JVM的悲观策略呢?
JVM自动触发GC(JVM的动态策略),是基于之前GC的频率以及旧生代的增长趋势来评估决定什么时候开始执GC;如果不希望JVM自行决定,可以通过-XX:UseCMSInitiatingOccupancyOnly=true来制定;
旧生代剩余的空间(available)大于新生代中使用的空间(max_promotion_in_bytes),或者大于之前平均晋升的old的大小(av_promo),返回false。cms gc是每隔一个周期(默认2s)就会做一次这个检查,如果为false,则不执行YGC,而触发cms gc。
对于悲观策略的解释换句话说:
当Minor GC时如果存活对象过多,无法完全放入Survivor区,就会向老年代借用内存存放对象,以完成Minor GC。在触发Minor GC时,虚拟机会先检测之前GC时租借的老年代内存的平均大小是否大于老年代的剩余内存,如果大于,则将Minor GC变为一次Full GC,如果小于,则查看虚拟机是否允许担保失败,如果允许担保失败,则只执行一次Minor GC,否则也要将Minor GC变为一次Full GC。说白了,新生代放不下就会借用老年代的空间来进行GC。
查看GC的log日志:(由于被重启了所以被请清理掉了,但是看到CMS后的内存比CMS前的还大),类似:
1 | 2015-03-26T18:18:06.349+0800: 7.092: [GC 7.092: [ParNew: 471872K->471872K(471872K), 0.0000420 secs]7.092: [CMS: 366666K->524287K(524288K), 27.0023450 secs] 838538K->829914K(996160K), [CMS Perm : 3196K->3195K(131072K)], 27.0025170 secs] |
ParNew的时间特别短,jvm在FGC前会首先确认old区是不是足够大,如果不够大,这次YGC直接返回,进行MSC。
综合以上判断可能是触发了JVM的悲观策略,所以在JVM的启动参数中添加了-XX:UseCMSInitiatingOccupancyOnly=true,在观察一段时间内存使用情况。
其他思考:
为什么生产环境只有小二后台出现了这个情况,其他应用没有呢?
目前我们小二后台配置的Heap的大小为1G,GC的策略为CMS方式,但是毕玄写过一片文章叫做《为什么不建议<=3G的情况下使用CMS GC》;而其他应用大部分配置的Heap区大小为2G;
淘宝线上应用基本配置均为4核8G,配置的Heap大小为4G,所以一般GC采用CMS,并开启UseCMSInitiatingOccupancyOnly,非常明确的GC策略,方便问题排查。
